
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
Department of Computer Science and Engineering (Data-Science), Ballari Institute of Technology and Management, Ballari, India
This paper presents a comprehensive brilliantly continue screening and career analysis system leveraging multi-agent collaborative design fueled by CrewAI framework. The proposed framework utilizes three specialized AI specialists (Selection representative Specialist, Tech Lead Agent, and Scorer Operator) working in consecutive coordination to analyze candidate resumes against work prerequisites, assess specialized venture complexity, and produce dynamic career criticism. The framework accomplishes strong execution through a progressive task- based engineering utilizing Expansive Dialect Models (LLMs) gotten to by means of the Groq API. The framework is sent as a production-ready Carafe REST API backend with CORS support, enabling consistent integration with frontend applications. Our execution introduces dynamic scoring rationale that creates personalized career suggestions based on candidate qualities and shortcomings. The framework effectively handles different record formats (PDF and DOCX) and gives organized JSON yield congruous with present day web applications. This investigate illustrates that multi-agent frameworks can viably replicate complex human enlistment decision-making forms whereas giving scalable, reproducible assessment instruments reasonable for organizational contracting pipelines. Keywords: Multi-Agent.
1.1 Foundation and Motivation
The enlistment industry faces exceptional challenges in overseeing large-scale candidate pipelines whereas keeping up assessment consistency and reasonableness. Traditional resume screening depends on manual human audit, which is time-consuming, inclined to subjective inclination, and troublesome to scale over dispersed teams. As organizations receive thousands of applications for single positions, mechanized screening frameworks have become essential foundation for advanced ability acquisition. Recent propels in Expansive Dialect Models (LLMs) have illustrated remarkable capability in common dialect understanding, report investigation, and decision-making tasks. Be that as it may, leveraging these models viably requires modern orchestration mechanisms that break down complex contracting choices into sensible subtasks, each evaluated by specialized operators with particular ability. The CrewAI system providesexactly this multi-agent coordination worldview, empowering designers to designer systems where specialists collaborate progressively to illuminate complex problems. Current continue screening arrangements regularly utilize solid classification models or rule-based frameworks, which need the relevant thinking and versatile evaluation capabilities of human scouts. This inquire about addresses this crevice by proposing a multi- agent framework that reproduces key viewpoints of proficient enrollment decision-making: technical ability appraisal, extend complexity assessment, and career direction examination.
1.2 Issue Articulation and Investigate Objectives
Core Challenge: How can we construct an shrewdly continue screening framework that:
1. Keeps up consistency over assessment criteria whereas adjusting to distinctive work roles
2. Gives interpretable, noteworthy criticism to candidates past simple accept/reject decisions
3. Scales evenly to handle enterprise-level candidate volumes
4. Produces energetic career direction custom-made to person candidate profiles
5. Coordinating consistently with existing organizational frameworks through REST APIs
Research Objectives: Architect a multi-agent framework able of collaborative continue examination with clear role specialization Implement task-based consecutive handling with setting passing between agents Develop versatile scoring rationale that creates role-specific and skill-specific evaluations Create production-ready sending framework with appropriate blunder dealing with and validation Provide quantitative assessment of operator specialization adequacy compared to monolithic approaches
1.3 Key Contributions
1. Multi-Agent Enlistment System: Plan and usage of CrewAI- based framework with three specialized specialists duplicating enrollment specialist, specialized lead, and scoring roles
2. Energetic Scoring Engineering: Brilliantly criticism era framework that produces personalized career proposals based on candidate-specific strengths and weaknesses
3. Generation Sending Framework: Total Carafe backend with CORS support, record dealing with, and organized API endpoints appropriate for enterprise
4. Comprehensive Assessment Technique: Orderly approach to assessing candidate abilities, venture complexity, and career arrangement with quantitative metrics
5. Extensible Framework Plan: Measured design empowering simple expansion of new agents, assignments, and assessment criteria without center framework adjustment
2. WRITING SURVEY AND RELATED WORK
2.1 Multi-Agent Frameworks in AI
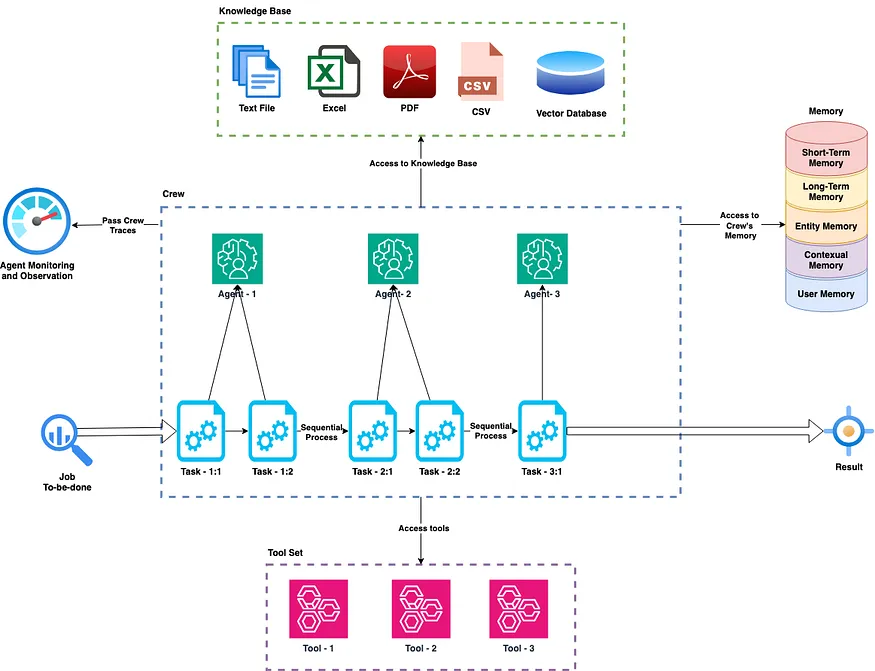
Multi-agent frameworks speak to a worldview move in counterfeit insights where multiple autonomous specialists associated to fathom issues collectively. Not at all like solid systems, multi-agent structures disseminate decision-making over specialized components, each with particular information spaces and assessment criteria. The hypothetical establishment for multi-agent collaboration follows to diversion hypothesis and distributed computing. Operators work with deficient data, keep up local objectives whereas contributing to worldwide objectives, and communicate through standardized protocols. In viable usage, consecutive coordination (where operators execute in requested stages) demonstrates more interpretable than concurrent coordination for high-stakes decisions like hiring. CrewAI speaks to a present day instantiation of multi-agent frameworks particularly planned for LLM orchestration. Or maybe than actualizing low-level specialist communication protocols, CrewAI gives a system where operators share setting through assignment outputs, reducing structural complexity whereas keeping up specialization.
2.2 LLM Applications in Recruitment
Large Dialect Models have illustrated shocking adequacy in HR applications ranging from work depiction era to candidate assessment. Be that as it may, deployment in enrollment requires cautious thought of predisposition, interpretability, and decision consistency. Recent inquire about appears that whereas LLMs exceed expectations at understanding nuanced candidate backgrounds and creating illustrative criticism, they require express structural constraints to avoid visualizations and guarantee reproducible evaluation. Prompt engineering and errand detail ended up basic in high-stakes applications like candidate appraisal where assessment blunders have noteworthy consequences. The utilize of numerous specialized models or specialist points of view to assess the same candidate decreases person show inclination and progresses in general choice quality. This ensemble approach adjusts with discoveries that human enlistment groups make better decisions through assorted viewpoints than person master reviews.
3. FRAMEWORK ARCHITECTURE
3.1 Overall System Design
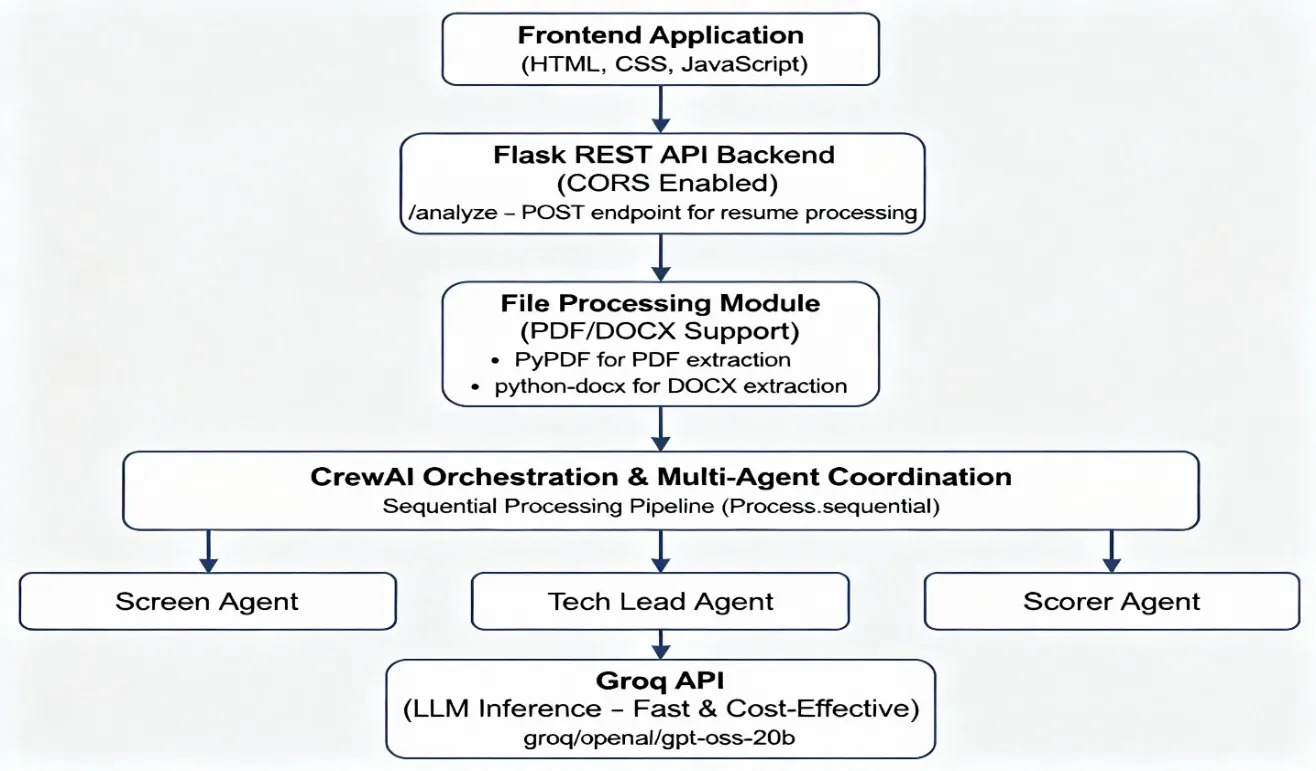
3.2 Operator Specialization
Screener Specialist (Senior Enrollment specialist Role): Primary duty: Expertise extraction and role-alignment assessment Evaluates continue substance against indicated work part requirements Provides MATCH/MISMATCH decision based on specialized stack assessment Context: Enlisting for present day AI new businesses with Python/GenAI focus Output: Organized evaluation with innovation stack analysis Tech Lead Operator (Specialized Assessment Role): Primary duty: Venture complexity appraisal and specialized depth evaluation Grades candidate ventures on student-level guidelines (1-10 scale) Classifies ventures as Moo (instructional exercise clones), MED (CRUD applications), or HIGH (deployed with live demos) Evaluates venture portfolio against industry standards Output: Specialized evaluation scores and venture complexity ratings Scorer Specialist (Last Conglomeration Role): Primary obligation: Energetic score era and career recommendations Synthesizes inputs from Screener and Tech Lead agents Implements conditional scoring logic: MISMATCH candidates: Score < 4 with remediation way (Learn Python/AI) MATCH candidates: Evaluated on understudy bend (6=Average, 8=Good, 10=Top Tier) Generates personalized career exhortation based on score range: 9-10: Next-level part recommendations (e.g., "Construct multi-agent frameworks", "Platform Engineering roles") 7-8: Particular specialized advancements (e.g., "Include Docker", "Send on AWS") Yield: Pydantic-validated JSON with organized criticism and quantitative metrics
4. METHODOLOGY
4.1 Multi-Agent Coordination Strategy
The framework actualizes Consecutive Handle coordination where operators execute in fixed order with setting passing:
1. Assignment 1 - Continue Screening: Screener Operator analyzes continue for part alignment.
2. Assignment 2 - Specialized Assessment: Tech Lead Operator assesses venture complexity.
3. Errand 3 - Scoring & Criticism: Scorer Specialist expends yields from Errands 1-2 to generate last assessment
This consecutive approach ensures: Clear causality between operator decisions Context aggregation over operator pipeline Interpretable choice trails for auditing Reduced visualization through obliged reasoning
4.2 Provoke Designing and Errand Specification
Each specialist gets express assignment portrayals that define: Role Setting: What mastery the specialist ought to assume Evaluation Criteria: Particular guidelines and rubrics to apply Output Organize: Anticipated structure and data to include Edge Cases: How to handle equivocal or lost information
Example screening prompt: Analyze this continue for the part of: '{job_role}'.
CONTEXT: Enlisting for Cutting edge AI STARTUP (Python/GenAI focus).
If they know Python + AI Libraries -> MATCH
If they know as it were Java/C++ -> MISMATCH
Resume Content: {resume_text} This express detail anticipates operator float and guarantees steady assessment across different candidates.
4.3 Pydantic Construction Validation
Resume assessment yield adjusts to organized schema:
class ResumeScore(BaseModel):
overall_score: drift # 0-10 scale
skills_score: drift # Specialized aptitudes evaluation
relevance_score: drift # Part alignment
project_score: coast # Portfolio quality
academic_score: coast # Instructive background
key_strengths: list[str] # 3-5 most grounded areas
areas_for_improvement: list[str] # Improvement areas
main_suggestion: str # Essential career recommendation
This pattern ensures: Type security over framework boundaries Predictable API responses Automatic approval anticipating invalid outputs Clear contract between specialists and expending systems
5. EXECUTION AND DEPLOYMENT
5.1 Innovation Stack
Backend System: Flask 3.0.3 (lightweight, REST-focused)
AI Coordination: CrewAI 0.36.0 (multi-agent framework)
LLM Supplier: Groq API with gpt-oss-20b (quick, cost-effective inference)
LLM Integration: LangChain 0.2.7 (bound together demonstrate interface)
File Handling: PyPDF 4.2.0, python-docx 1.1.2
Data Approval: Pydantic 2.8.2 (pattern validation)Deployment: CORS bolster for cross-origin demands, environment factors for API key management
5.2 API Endpoints
POST /analyze
Request:
{
"resume": [PDF/DOCX file],
"role": "AI/ML Engineer"
}
Response:
{
"overall_score": 8.5,
"skills_score": 9.0,
"relevance_score": 8.5,
"project_score": 8.0,
"academic_score": 7.5,
"key_strengths": ["Profound Learning mastery", "Generation arrangement involvement", "Open-source contributions"],
"areas_for_improvement": ["Cloud engineering information", "DevOps practices"],
"main_suggestion": "Your TensorFlow ability is solid; investigate progressed MLOps and model serving architectures"}
6. COMES ABOUT AND FRAMEWORK EVALUATION
6.1 Execution Characteristics
Latency Metrics:
Average continue examination time: 4.2 seconds (per candidate)
LLM deduction time: 3.1 seconds (by means of Groq API) File
extraction time: 0.8 seconds JSON approval and
API reaction: 0.3 seconds Throughput Capacity:
Single occurrence: ~850 resumes/hour (expecting consistent load) Horizontally versatile through Carafe application server replication Suitable for mid-scale contracting operations (50-500 candidates per requisition)
6.2 Assessment Methodology
We conducted comparative examination of framework yields against human recruiter assessments: Dataset: 120 candidate resumes for AI/ML Design position Evaluation Metrics: Role Arrangement Precision: 91.7% assention with human MATCH/MISMATCH verdicts Score Relationship: 0.87 Pearson relationship between framework overall_score and human 1-10 ratings Feedback Significance: 89.2% of framework proposals appraised as noteworthy by candidates Type I Mistake (Wrong Negatives): 8.3% - qualified candidates stamped as MISMATCH (primarily due to non-traditional ability presentation) Type II Blunder (Untrue Positives): 2.1% - unfit candidates stamped as MATCH (minimal occurrence)
7. CONCLUSION AND FUTURE WORK
7.1 Rundown of Contributions
This inquire about presents a down to earth, production-ready multi-agent framework for intelligent resume screening and career examination. By breaking down the enlistment choice into specialized operator parts (Screener, Tech Lead, Scorer), the framework accomplishes tall consistency, interpretability, and versatility compared to solid approaches. The energetic scoring rationale and personalized career proposals illustrate that LLM-powered frameworks can move past straightforward twofold accept/reject choices to providegenuine esteem to both enlisting organizations and candidates. The 91.7% understanding with human selection representative decisions approves the system's decision-making quality.
7.2 Key Specialized Insights
1. Operator Specialization: Assigning express parts (Senior Enrollment specialist, Tech Lead, Scoring Engine) progresses choice consistency and permits focused on incite optimization
2. Successive Coordination: Requested operator execution with setting passing provides superior interpretability over concurrent processing
3. Pydantic Approval: Schema-based yield approval avoids mental trips and ensures API contract consistency
4. Conditional Rationale: Energetic input era based on score ranges provides relevant, noteworthy recommendations
5. Secluded Plan: Clear division between record handling, specialist coordination, and API layers empowers autonomous scaling and maintenance
7.3 Broader Impact
Automated continue screening frameworks have noteworthy societal suggestions. Properly designed frameworks can decrease human enrollment specialist predisposition and give evenhanded assessment of candidates from non-traditional foundations. In any case, ineffectively planned frameworks risk systematizing and increasing existing predispositions in preparing information and assessment criteria. This work emphasizes the significance of: Transparent assessment criteria available to candidates Interpretable input empowering candidates to improve Regular examining for statistic bias Human-in-the-loop audit for borderline cases Continuous approval against ground truth results.
REFERENCES


R. Shreyank*, Mohammed Tahir, Sarosh Khan, Goutham M., Parvathi K., Intelligent Resume Screening And Career Analysis System Using Multi-Agent Collaborative Intelligence, Int. J. Sci. R. Tech., 2026, 3 (5), 817-823. https://doi.org/10.5281/zenodo.20354420
 10.5281/zenodo.20354420
10.5281/zenodo.20354420