
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
MIT School of Computing, MIT ADT University, Loni, Pune, Maharastra, India
Digital image processing, a subset of digital signal processing, has widespread adoption across various fields due to its versatility and benefits. Leveraging computer science, programming, and artificial intelligence, enables the manipulation and analysis of digital images to extract valuable information. This paper explores the extensive applications of digital image processing techniques, encompassing areas such as image sharpening and restoration, medical imaging, remote sensing, robotics, color processing, pattern recognition, and more. With its extreme flexibility, digital image processing facilitates linear and nonlinear processes, catering to diverse needs across disciplines. Moreover, the advancements in image processing systems contribute to improving pictorial information for human interpretation and enable autonomous machine perception through enhanced image data storage, transmission, and representation. This paper aims to define the scope of digital image processing, elucidate its methodologies, and showcase its pivotal role in advancing research across frontier areas.
In today?s technologically advanced landscape, computers have become indispensable tools for facilitating control over engineering systems, data collection, analysis, processing, and decision-making processes across various industries. Digital image processing, a fundamental branch of computer science, is dedicated to manipulating digital signals representing images captured by digital cameras or scanners. Formerly known as image processing, its integration with computer technology underscores its pivotal role in intelligent systems where critical decisions are made.Digital image processing encompasses numerous applications across technical, industrial, urban, medical, and scientific domains. Its primary branches focus on image enhancement and machine vision. These techniques aim to improve visual quality, ensure accurate display environments, and interpret image content for purposes such as robotics and image analysis. In essence, digital image processing processes two-dimensional signals to extract meaningful information, serving as a cornerstone for understanding and manipulating visual data in the digital era. An image is defined by the mathematical function f(x,y)f(x, y)f(x,y), where xxx and yyy represent the two coordinates horizontally and vertically. Image processing involves operations to enhance images or extract useful information. Rapid advancements in image processing systems hold the promise of developing ultimate machines capable of performing visual functions akin to those of living beings.
Some major fields in which digital image processing is?widely?used are?mentioned below.
Security?purposes:
Image sharpening and restoration for?the Medical?field, Remote sensing?Transmission and encoding?Machine, Robot vision?Color?processing, Pattern recognition?Video processing?Microscopic?Imaging.
LITREATURE SURVEY
Digital image processing involves various stages designed to manipulate images for a range of purposes, which can be broadly categorized into two areas: methods that provide image inputs and outputs, and those that extract attributes from images. The process begins with image acquisition, often followed by preprocessing steps such as scaling. Image enhancement seeks to reveal obscured details or emphasize features of interest, though this process can be subjective. In contrast, image restoration relies on mathematical models of image degradation to achieve objective improvements. Color image processing focuses on studying color models and processing techniques in digital domains, an increasingly important area due to the growing prevalence of digital images. Wavelets play a significant role in facilitating image processing tasks.
representation and compression. Compression techniques are essential for effective storage and transmission of images, frequently utilizing established standards such as JPEG. Morphological processing plays a key role in extracting components that are vital for shape representation. Segmentation is an important yet challenging task that involves partitioning images, laying the groundwork for subsequent processing stages. Following segmentation, representation and description transform raw image data into forms that are more suitable for computer analysis. Recognition then assigns labels to identified objects based on their descriptors, which is fundamental for effective object identification. Additionally, geometric adjustments and various processing techniques, including security measures, contribute to enhancing both the quality and security of images.
Image processing can be categorized into three general levels:
1. Low-level processing: This category involves basic tasks such as noise cancellation, image filtering, and contrast adjustments.
2. Intermediate-level processing: In this phase, the input is typically an image, while the output consists of attributes related to image objects, such as edges, contours, and object recognition.
3. High-level processing: This advanced stage entails understanding the relationships between detected objects, interpreting scenes, and performing analyses akin to those carried out by the human visual system.
The field of image processing encompasses a variety of techniques aimed at manipulating images for diverse applications, including picture processing, pattern recognition, and image interpretation. Picture processing focuses on improving image quality by addressing issues like overexposure, underexposure, and blurriness, often using techniques such as contrast enhancement. Pattern recognition involves generating descriptions or classifying images into specific categories, exemplified in applications like automatic mail sorting. Given the rise of digital information, it is critical to view image processing within the broader context of information processing, where images play a pivotal role.
Enhancement and restoration techniques further contribute to image quality improvement. Enhancement methods like contrast modification, blurring correction, and noise removal aim to refine image clarity, while restoration techniques are dedicated to correcting specific forms of degradation, often relying on formal methods like filter theory. Segmentation techniques help break images into segments to facilitate data compression and analysis, whereas feature extraction identifies specific characteristics be they natural or artificial within images for further processing or retrieval.
In the domain of defense surveillance, image processing is particularly valuable for monitoring land and ocean environments through aerial surveillance methods. Segmenting objects in aerial imagery allows for effective parameter extraction, assisting in the classification and localization of objects such as naval vessels. Content-based image retrieval plays a crucial role in efficiently searching and retrieving images from extensive databases based on their intrinsic content. Moreover, moving-object tracking is essential for measuring motion parameters and obtaining visual records, typically employing motion-based predictive techniques. Understanding the neural aspects of the visual sense illuminates how optic nerves convey signals and how the brain processes visual information, highlighting the significance of differentiating in contrast phenomena and the brain's integral role in perception.
Image Acquisition, Preprocessing, and Feature Extraction
Creating a facial recognition system to identify familiar soldiers and mark unknown individuals as potential threats demands careful execution at every stage. Below is a detailed overview of the processes involved:
Image Acquisition
This initial phase involves capturing raw image data from various input sources.
Challenges and Considerations:
Cameras: High-resolution CCTV or specialized security cameras.
Infrared or Thermal Cameras: Beneficial for low-light or nighttime situations.
Video Streams: Ongoing footage needed for frame-by-frame analysis.
Lighting Variations: Systems should manage low light, glare, and shadowed areas.
Camera Angle and Distance: Faces need to be effectively captured from various angles and distances.
Occlusions: Manage situations where faces may be partially obstructed (e.g., by helmets, masks, or natural barriers).
High-Resolution Cameras: Ensure that the images captured have enough detail for reliable recognition.
Processing Unit: Use edge devices for preliminary processing to minimize bandwidth usage if using cloud processing.
Recommendations:
Preprocessing
Raw images must be refined and standardized to provide consistent input for the machine learning model.
Techniques and Steps:
Challenges Addressed:
This resolves inconsistencies stemming from different environments and ensures uniformity in the data, minimizing the risk of bias due to low-quality input images.
Tools/Frameworks:
Feature Extraction
This phase focuses on transforming the preprocessed image into a concise and meaningful representation for classification or recognition.
Techniques:
Key Features:
Image Classification
Classification in an image processing system is essential for enabling the automatic identification and categorization of objects, scenes, or patterns in images. It forms a fundamental part of various practical applications, such as medical diagnosis, facial recognition, self-driving cars, and content moderation.
Importance of Classification in Image Processing Systems
Steps in Developing an Image Classification System
Clearly define the objective (e.g., identifying disease in plant leaves) and the categories (e.g., healthy, diseased).
Gather labeled image data representative of the classification task.
Tools: Digital cameras, satellite systems, or online datasets (e.g., CIFAR, ImageNet).
Use machine learning models or techniques to extract relevant features (e.g., edges, textures, or specific patterns).
Choose a classification algorithm:
Traditional Methods: Support Vector Machines (SVMs), Random Forests.
Deep Learning Methods: Convolutional Neural Networks (CNNs), Vision Transformers (ViTs).
Different Methods of Image Recognition and Image Compression
Image processing techniques encompass a broad array of methods used for diverse applications, ranging from basic noise reduction and image filtering to more advanced tasks like object recognition and scene interpretation. These techniques are categorized into three main levels:
Techniques and Applications in Image Processing
Image Compression
Image compression methods are critical for minimizing storage and transmission requirements. Widely used techniques like JPEG and MPEG employ tailored compression algorithms for still images and moving pictures, respectively. Image resolution encompasses pixel resolution, spatial resolution, and temporal resolution, all of which play a crucial role in determining the clarity and detail of images. Spatial resolution affects the ability to distinguish between closely spaced objects, while temporal resolution impacts the accuracy of motion representation in videos.
System Development and Validation
When creating and validating an image processing system intended to recognize known soldiers while marking unrecognized individuals as potential threats, it is crucial to focus on accuracy, fairness, and robustness. Below is a comprehensive overview of the development and validation of this system tailored to its specific application.
System Development
1. System Architecture
2. Data Pipeline Design
3. Model Development
Edge Devices: Deploy efficient models on edge devices like drones or security cameras for real-time processing.
Cloud Integration: Transfer resource-intensive tasks (e.g., training and complex validation) to the cloud.
Latency Optimization: Enhance processing times for instantaneous threat detection, taking hardware limitations into account.
System Validation
1. Model Performance Validation
2. Robustness Testing
. Ethical and Bias Validation
4. Scalability and Stress Testing
5. Security Validation
6. Real-World Validation
Resources Needed
1. Data Resources
2. Computational Resources
Face Recognition Libraries: FaceNet, Dlib, or DeepFace.
ML Frameworks: TensorFlow, PyTorch, or OpenCV.
Monitoring Tools: Prometheus for system oversight and MLflow for model tracking.
3. People
4. Processes
Functioning of the Model
The model employs YOLOv8, an advanced framework for real-time object detection, to identify soldiers within images. The accompanying code demonstrates a comprehensive process for performing inference on both photographs and live video feeds using a custom-trained YOLOv8 model. A custom dataset was annotated with the assistance of Roboflow to accurately label instances of soldiers. This section elaborates on the code?s operation and its significance concerning the output image, where soldiers are marked with bounding boxes.
How YOLOv8 Functions
YOLOv8 (You Only Look Once, version 8) builds on the progress of previous versions, focusing on both speed and precision. The model analyzes an image in a single pass through a deep neural network, dividing it into grid cells while predicting bounding boxes, class probabilities, and object confidence scores.
The main components of YOLOv8 are as follows:
The input image is resized to a specified dimension (e.g., 640x640 pixels) to meet the model's input criteria.
Normalizing pixel values ensures uniform input scaling for consistent performance.
A backbone network, such as CSPDarknet, extracts features from the image.
Various layers capture distinct attributes, ranging from edges to intricate textures.
The model predicts bounding boxes, objectness scores, and class probabilities for every grid cell.
Post-processing methods, such as Non-Maximum Suppression (NMS), remove overlapping boxes and retain the most relevant predictions.
Output
? ? ? ?
? ? ? ? ? ? 
? ? ? ?
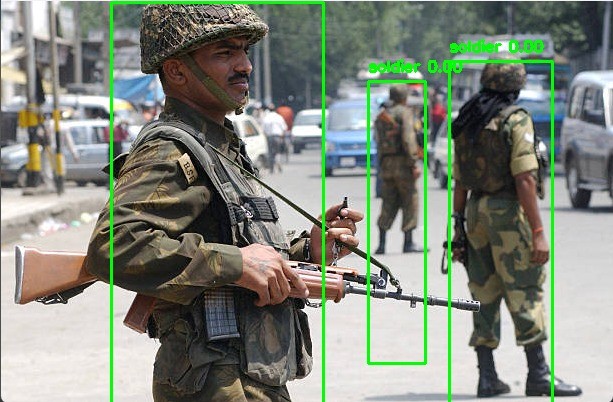
Image (a) Showing the image of multiple identified soldiers
The model generates the coordinates of bounding boxes, class IDs, and confidence scores for each detected object. In the resulting image, bounding boxes surrounding the identified soldiers are shown, with labels like "soldier 0.00" illustrating these predictions. The confidence score reflects the model?s certainty about its detection.
? ? ? ?
? ? ? ? ? ? 
? ? ? ?
Image (b) Showing the image of one identified soldier among many ?unknown? individuals
Here, Image(b), tells us that the trained model can respond correctly to complex situations by distinguishing perfectly, where there are unidentified individuals (labeled ?unknown 0.00?)? along with the identified soldiers. It signifies that the model is thoroughly trained over a large dataset of soldiers in uniform as well as the images of unidentified civilians.
The essence of the application focuses on:
A user-friendly GUI, developed with Tkinter, enables users to engage with the program effortlessly, eliminating the need to interact with the underlying code.
Workflow
The application begins by loading a pre-trained YOLOv8 model.
This model has been fine-tuned on a dataset specifically designed to detect Indian soldiers, providing knowledge of object categories and the ability to generalize detections to new images or video streams.
? ? ? ?
? ? ? ? ? ? 
? ? ? ?
Image(c) Providing the user with 2 alternatives: (i) Image inference and (ii) Live Webcam Inference
Processing Images
(i) When a User Selects an Image:
(ii) Processing Live Webcam Feed:
The program captures video frames in real time.
Each frame is analyzed by the YOLOv8 model for inference.
Predictions (bounding boxes, labels, and scores) are superimposed onto the live video feeds.
The marked frames are shown in a continuous video stream until the user exits the application.
User Interaction
The GUI provides a straightforward method to access the program's features:
Buttons enable users to select an image or initiate the webcam feed.
A separate button allows the user to terminate the application.
Key Features
How It Relates to the Output
Employing YOLOv8 to identify features in the image corresponding to soldiers.
Rendering the predictions on the image using OpenCV.
General Workflow
The model is loaded, and the GUI is set up.
If the user selects an image, it is processed and displayed with detections.
If the user initiates the live feed, the webcam stream is processed frame-by-frame for real-time detection.
The program exits smoothly when the user selects the exit option.
Drawbacks
1. Performance Gaps
Challenge:
Impact:
Approach to Address:
2. Real-Time Challenges
Challenge: Dynamic environments, such as border patrol or battlefield operations, require real-time processing. Latency can delay threat recognition.
Impact:
Delayed recognition may provide adversaries with a strategic advantage.Real-time demands strain computational resources.
Approach to Address:
Use optimized deep learning models like MobileNetV3.
Employ hardware accelerators like NVIDIA Jetson Nano or Coral Edge TPU for edge processing.
3. Scalability Issues
Challenge:
Impact:
Approach to Address:
4. Resource Constraints
Challenge:
Impact:
Approach to Address:
5. Integration Deficiencies
Challenge:
Impact:
Approach to Address:
FUTURE WORK
System Design and Development
Pipeline Implementation
1. Image Acquisition




Shivam Kumar, Shraddha Kashid, Enrique Anthony, Aditya Pardeshi, Image Classification System, Int. J. Sci. R. Tech., 2024, 1 (12), 66-75. https://doi.org/10.5281/zenodo.14312670
 10.5281/zenodo.14312670
10.5281/zenodo.14312670