
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
No. 114/10, Seniamman Koil Street, Tondiarpet, Chennai 600081
The rapid adoption of Retrieval-Augmented Generation (RAG) in enterprise environments marks a critical shift toward democratized, generative knowledge management. However, deploying these systems across flat corporate data repositories introduces severe architectural vulnerabilities, specifically regarding access control bypasses and the erosion of data pedigree. Current literature heavily indexes on algorithmic optimization, leaving a significant gap in operational governance. This paper introduces the Enterprise RAG Trade-off Matrix, a conceptual framework that maps the competing axes of knowledge velocity against zero-trust security and compliance requirements. We establish that securing enterprise RAG requires a paradigm shift toward "Policy-Before-Retrieval" architectures, utilizing deterministic, participant-aware access controls and continuous metadata governance. Finally, we outline the "Velocity vs. Vulnerability Frontier," calling for future empirical research to quantify the human-centric impacts of generative AI on cognitive performance and blind compliance in corporate settings.
The structural evolution of corporate knowledge management is currently defined by a rapid transition from static, keyword-based search systems to active, generative artificial intelligence infrastructure [1]. At the core of this transformation is Retrieval-Augmented Generation (RAG), an architectural design that couples the parametric capabilities of large language models (LLMs) with non-parametric, authoritative enterprise databases [2]. By grounding model generation in real-time document retrieval, RAG successfully mitigates the inherent vulnerabilities of vanilla LLMs, specifically addressing the temporal knowledge cutoff and the propagation of inaccurate, fabricated outputs known as hallucinations [3, 4]. This paradigm shift redirects the LLM to retrieve relevant information from pre-determined knowledge sources at inference time, allowing organizations to maintain an up-to-date "source of truth" without the prohibitive costs associated with model fine-tuning [5, 6].
The primary organizational driver for this shift is data democratization—the process of providing authorized employees with frictionless, self-service access to high-quality, governed data to empower decentralized decision-making [7, 8]. However, the rapid deployment of RAG at scale introduces critical side effects that threaten the integrity of the enterprise information ecosystem. Organizations often attempt to democratize knowledge by flatly indexing corporate data without re-architecting their access control frameworks, leading to the bypassing of traditional permissions and the systematic erosion of data pedigree [9, 10]. Current Information Systems (IS) research has frequently over-indexed on algorithmic optimizations, such as chunking strategies and semantic re-ranking, while neglecting the operational trade-offs and governance requirements necessary for secure production environments [11, 12]. This paper addresses this gap by introducing a conceptual trade-off matrix designed to assist enterprise architects in balancing the goals of democratization against the mandates of zero-trust security and contextual integrity.
2. MATERIALS AND METHODS
To construct this conceptual framework, we analyzed the standard enterprise RAG pipeline, which consists of four primary stages: data extraction (ingestion), data transformation (chunking and embedding), prompt and search (retrieval), and LLM generation [13, 14]. We specifically evaluated the system-level vulnerabilities that emerge at the ingestion and retrieval stages where traditional security perimeters often collapse in corporate environments.
2.1 Ingestion-Stage Bottlenecks and Data Staleness
Vulnerabilities are frequently "front-loaded" at the extraction stage [15]. Organizations often treat internal data sources as inherently trustworthy, failing to implement robust validation mechanisms [15]. This leads to "passive poisoning," where malicious or unverified text from internal repositories is crawled and indexed into the vector database [15]. Furthermore, the mathematical segmentation of documents into semantic chunks often strips information of its temporal, geographic, and hierarchical context, leading to "contextual pollution" [15, 16]. A significant operational risk is "silent staleness," where the pipeline retrieves a document that is semantically relevant but contains outdated facts [17, 18]. Because vector similarity has no temporal dimension, a retriever may surface a deprecated policy with a high similarity score, leading the LLM to generate a confident but incorrect answer [18, 19].
2.2 Retrieval-Stage Vulnerabilities and RBAC Bypasses
The most acute vulnerability in enterprise RAG lies in the access control asymmetry between traditional Identity and Access Management (IAM) systems and vector database queries [10, 20]. Most vector databases are "permission-blind," storing text chunks without their corresponding security context [21]. In a simplistic deployment, the retrieval mechanism fetches semantic matches regardless of the user's actual privileges, allowing unauthorized employees to retrieve sensitive data—such as executive compensation or HR records—via indirect similarity queries [10, 20, 22]. This creates a path for indirect exfiltration, where the model synthesizes restricted content into its response [20]. To mitigate this, enterprise AI must adopt Zero Trust principles, moving away from perimeter-based trust to a model of continuous verification and participant-aware access control [23, 24, 25]. Secure deployment requires that any content retrieved must be authorized for all users involved in an interaction before it is fed to the LLM [23, 26].
3. RESULTS
Based on our architectural analysis, we formalize the competing axes of the enterprise RAG trilemma into the Enterprise RAG Trade-off Matrix (Table 1). Optimizing for democratization or velocity inevitably introduces friction in security or pedigree, creating a structural boundary that dictates the constraints of the system [1, 27].
|
The Enterprise Objective |
The RAG Architectural Benefit |
The Critical Enterprise Side-Effect / Vulnerability |
The Required Governance Mitigation |
|
Knowledge Democratization |
Decouples knowledge from model weights; provides near-zero Time-to-Information (TTI) via natural language [1]. |
Permission Bypass: Unauthorized retrieval of sensitive data via blind semantic similarity [10, 20]. |
Participant-Aware Access Control: Deterministic pre-retrieval filtering of chunks based on active user identity [10, 20]. |
|
Real-time Decision Support |
Grounded generation using real-time retrieval from live enterprise state [28]. |
Silent Staleness: Semantic similarity is structurally blind to time; LLM synthesizes outdated facts with high confidence [17]. |
Streaming Change Data Capture (CDC): Continuous index updates and composite freshness scoring ( 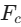
|
|
Operational Efficiency (Low TCO) |
Shifts computational load from expensive model fine-tuning to modular retrieval [6]. |
The "Scale Cliff": Managed serverless vector storage costs scale non-linearly with volume and cardinality [30]. |
Hybrid Storage Architecture: Store minimum metadata in vector index; retrieve full records from relational stores via vector IDs [30]. |
|
Regulatory Compliance & Auditability |
Grounded outputs with inline citations to authoritative document segments [5, 6]. |
Loss of Provenance: Chunking fragments documents and often strips metadata (authorship, version, jurisdiction) [31]. |
Chunk-level Metadata Tagging: Persistent injection of source-first identifiers and page-level provenance [1, 31]. |
Table 1: The Enterprise RAG Trade-off Matrix
4. DISCUSSION
The enterprise architect must interpret this matrix through the lens of the "Velocity vs. Vulnerability Frontier," a conceptual boundary where the speed of information access is mapped against the escalating risk of compliance or security failure [32]. While "flat" RAG architectures prioritize democratization and rapid time-to-value, they inherently expand the corporate threat surface by treating internal data sources as uniformly trustworthy [1, 4]. To remain on the stable side of this frontier, deployment decisions must move away from probabilistic post-generation guardrails toward deterministic safeguards embedded directly into the retrieval pipeline [9, 10].
To resolve the acute risk of unauthorized data exposure, architects must enforce a paradigm shift to Identity-Centric Access Control, where every retrieval operation is gated by real-time validation against native Identity and Access Management (IAM) endpoints [9, 20]. Relying on post-filtering is fundamentally unsound; if sensitive data enters the LLM's context window, sophisticated users can deduce confidential information via indirect exfiltration or inference attacks [1, 10]. Consequently, a production-grade RAG deployment must adopt a "Policy-Before-Retrieval" standard, ensuring that the AI never "sees" unauthorized content during the semantic scoring phase [1, 9].
Finally, maintaining operational reliability requires treating the RAG knowledge base as a governed artifact rather than a static index [29]. Because vector similarity has no temporal dimension, systems are perpetually vulnerable to "freshness rot," where the model confidently serves deprecated facts that are semantically relevant but factually invalid [17, 29]. Mitigating this necessitates the implementation of Streaming Change Data Capture (CDC) to replace batch ingestion, coupled with metadata-driven evaluation heuristics that force a system refusal if the retrieval confidence or document version flags context as deprecated [1, 4, 17]. This ensures that the RAG pipeline functions not just as a retrieval tool, but as a robust Information System capable of preserving contextual integrity at enterprise scale [1].
CONCLUSION
The structural transition to Enterprise Retrieval-Augmented Generation (RAG) represents a fundamental evolution in organizational knowledge management that extends far beyond simple algorithmic optimization [1, 4]. This analysis establishes that the effective integration of generative AI within the corporate environment is primarily a challenge of Information Systems governance and data engineering rather than a mere selection of large language models [1, 33]. The "Enterprise RAG Trade-off Matrix" introduced in this paper provides a necessary architectural boundary for decision-makers, proving that the pursuit of knowledge democratization cannot scale safely without deterministic, identity-centric access controls and the rigorous maintenance of data pedigree [1, 10]. By enforcing a "Policy-Before-Retrieval" standard and treating the retrieval layer as a governed control plane, enterprise architects can mitigate the acute risks of indirect data exfiltration and "silent staleness" that otherwise plague flat RAG implementations [1, 17, 20].
While this conceptual framework delineates the structural boundaries of the enterprise RAG trilemma, future empirical research is urgently required to validate these trade-offs within live operating environments [1, 32]. Future scholarship must move beyond traditional system-level metrics, such as retrieval latency and token efficiency, to measure human-centric business impacts and cognitive outcomes [32]. Specifically, we call for rigorous A/B testing between legacy search systems and generative RAG architectures to quantify the rate of "blind compliance"—a phenomenon where employees execute tasks based on convincing but hallucinated or outdated AI summaries without verifying primary source citations [32, 34]. Longitudinal studies should employ mixed-methods designs to evaluate how RAG retrieval influences human cognitive performance, task velocity (TTI), and the potential decay of deep domain expertise among the workforce [32]. Investigating this "Velocity vs. Vulnerability Frontier" will allow researchers to identify the optimal friction points where user interfaces must intentionally force source verification to prevent critical compliance failures, ultimately providing a validated blueprint for aligning generative technology with sustainable organizational competence [1, 32].
ACKNOWLEDGEMENT
The authors declare that no specific funding or support was received for this conceptual study.
CONFLICTS OF INTEREST
The authors declare no conflicts of interest.
REFERENCES

Alfred Patrick Patric*, A Conceptual Framework For Enterprise RAG Trade-Offs: Balancing Democratization Against Security And Data Pedigree, Int. J. Sci. R. Tech., 2026, 3 (6), 1838-1842. https://doi.org/10.5281/zenodo.21069045
 10.5281/zenodo.21069045
10.5281/zenodo.21069045