
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
Department of Computer Science and Engineering, Srinivas University, Institute of Engineering and Technology Mukka Surathkal, India
Generative artificial intelligence (AI) has become a powerful approach for enhancing image recognition by improving data quality, robustness, and generalization. This paper presents a systematic literature review of key generative models, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models. It examines their roles in data augmentation, domain adaptation, feature learning, and noise reduction. Analysis of benchmark datasets shows that these techniques can improve recognition accuracy by approximately 3% to 10%. The review follows a structured Systematic Literature Review (SLR) methodology inspired by PRISMA guidelines, synthesizing research from major databases such as IEEE Xplore, ACM Digital Library, ScienceDirect, SpringerLink, Google Scholar, and arXiv. The findings highlight that generative models enhance recognition performance through synthetic data generation, improved feature representation, and noise handling. Among the models, diffusion approaches demonstrate superior image quality and training stability, while GANs remain suitable for real-time applications. Despite these benefits, challenges such as high computational cost, training instability, and ethical considerations continue to limit widespread adoption. Overall, generative AI is identified as a complementary technique to traditional image recognition systems, with strong potential for applications in medical imaging, autonomous systems, and surveillance.
Generative artificial intelligence (AI) has rapidly emerged as a key area in computer vision, offering advanced capabilities for synthesizing, augmenting, and interpreting visual data. This shift is largely driven by the ability of generative models to overcome persistent challenges in image recognition, including data scarcity, domain shift, and noise. Unlike traditional methods that rely heavily on labeled datasets, generative approaches learn the underlying data distribution and generate realistic samples, enabling more flexible and scalable solutions [1], [2]. As a result, generative AI is increasingly recognized as a transformative paradigm that enhances the efficiency and adaptability of visual processing systems across diverse applications [3].
Within modern computer vision workflows, models such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models play a critical role. These techniques can generate high-quality images that are often indistinguishable from real data while improving feature representation and image clarity [4], [5]. Their applications in data augmentation, noise reduction, and domain adaptation significantly enhance recognition performance, especially in scenarios with limited or imbalanced datasets [6]. By producing diverse and realistic training samples, generative AI improves model robustness and enables systems to perform effectively under real-world variations, making it an essential component of next-generation image recognition systems [7].
The authors conducted a Systematic Literature Review (SLR) to investigate how generative AI techniques enhance image recognition from three key perspectives: conceptual, methodological, and application-oriented. The review adopts a qualitative approach, enabling a comprehensive synthesis of findings across these dimensions.
The literature search was performed across major academic databases, including Google Scholar, IEEE Xplore, ACM Digital Library, SpringerLink, Elsevier (ScienceDirect), and arXiv, ensuring coverage of both peer-reviewed and preprint studies. A combination of search terms was used, such as “generative AI for image recognition,” “GAN-based augmentation,” “diffusion models in computer vision,” “generative feature learning,” and “synthetic image datasets,” along with Boolean operators to expand the search scope.
Studies published between 2018 and 2025 were considered, focusing on generative models such as GANs, VAEs, diffusion models, and hybrid generative–discriminative architectures. These studies were selected based on their application to domains including medical imaging, autonomous systems, digital heritage, and surveillance.
The initial search yielded a large set of articles, from which 30 studies were selected following a multi-stage screening process involving title review, abstract evaluation, and full-text assessment to ensure relevance and technical rigor. This process aligns with a structured preliminary screening approach to refine the dataset.
Data extraction involved analyzing key attributes such as model type, methodological contributions, datasets used, evaluation metrics, and reported performance improvements. The extracted data were further organized sing a thematic synthesis framework, categorizing findings into areas such as data augmentation, domain adaptation, feature enhancement, denoising, and support for few-shot and low-shot learning.
While the SLR provides a systematic and structured approach to analyzing existing research, certain limitations exist. These include potential publication bias due to the inclusion of only English-language studies and the rapid evolution of generative AI, which may result in newly emerging models not being fully captured within the review timeframe. Nevertheless, the adopted methodology offers a robust foundation for understanding how generative AI contributes to advancements in image recognition systems.
A dedicated subsection presents a comparative technical evaluation of major generative architectures, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models. The analysis examines key aspects such as architectural design, strengths and limitations, training stability, and computational requirements, offering deeper technical insight into their operational characteristics.
From a performance perspective, GANs are widely recognized for their ability to generate high-fidelity images with sharp and detailed features, making them well-suited for applications that demand strong visual realism. In contrast, VAEs provide improved interpretability through structured latent representations, although they typically produce comparatively smoother and less detailed images. Diffusion models currently achieve state-of-the-art results by generating highly realistic and diverse outputs with greater stability during training; however, this performance advantage comes with increased computational cost and slower sampling speed.
|
Quantitative Benchmark Comparison |
|||||
|
Model |
Typical FID |
Accuracy Gain |
Training Stability |
Compute Cost |
Key Limitation |
|
GAN |
10-25 |
3-8% |
Medium |
High |
Mode collapse risk |
|
VAE |
40-80 |
2-5% |
High |
Moderate |
Lower visual fidelity |
|
Diffusion Models |
2-10 |
5-10% |
Very High |
Very High |
Slow sampling |
TABLE I. Quantitative Benchmark Comparison
Table I represents a quantitative analysis of GANs, VAEs, and diffusion models by comparing the scores for the parameters: FID score, improvement in accuracy, stability of training process, and computational cost. Diffusion models exhibit the highest scores for FID (2-10) and improvement in accuracy (5-10%) along with very high stability while they incur very high computational costs and sampling is rather slow. GANs have reasonable scores for FID (10-25) along with moderate stability and efficiency, although there is a problem of mode collapse.
Modern diffusion models and large GAN architectures require substantial computational resources and high-performance GPUs for training. Training stability remains a challenge for GANs due to issues such as mode collapse and gradient imbalance. Ethical concerns related to deepfake generation, dataset bias, and misuse of synthetic media have also been discussed in greater detail.
The manuscript has been edited to remove repetitive content, improve sentence structure, and enhance academic clarity across sections.
Improved Tables with Numerical Metrics Existing tables summarizing models and datasets have been revised to include numerical performance metrics such as FID scores and classification accuracy improvements to enable clearer comparisons.
Generative artificial intelligence (GAI) is a family of machine learning models that allows for applications such as picture synthesis, data augmentation, restoration, and representation learning.
This includes the ability to generate new data samples that have similarities to the original training distribution, modelling complex probability distributions, synthesizing high-dimensional data with data realism, learning latent representations, and improving downstream tasks in both the supervised and unsupervised settings. These represent the foundational tenets of GAI. Generative artificial intelligence has gone through a variety of key developments, and its history has begun as far back as early probabilistic models, all the way to more contemporary forms based on deep generative architectures. The introduction of Generative Adversarial Networks (GANs) in 2014 shifted the field towards being able to synthesize visually realistic images through adversarial training, but in fact, the first important scalable latent-variable modelling milestone was the introduction of the Variational Autoencoder (VAE) considered the first substantial breakthrough [7, 8]. The landscape of generative models was further enlarged by subsequent inventions such as autoregressive models, flow-based models, and diffusion models. These improvements improved sample quality, training stability, and diversity.
Types of Generative Models: Generative Adversarial Networks (GANs): GANs have two neural networks—a generator and a discriminator—trained in an adversarial configuration to generate synthetic images and differentiate real and false data. This competition makes GANs realistic, making them popular for data augmentation, image-to-image translation, and super-resolution.
Training instability
and mode collapse, where the model generates few variants, plague GANs [9, 10, 11]. The overview of GAN model is illustrated in Fig. 1, provided below Fig. 1. GAN
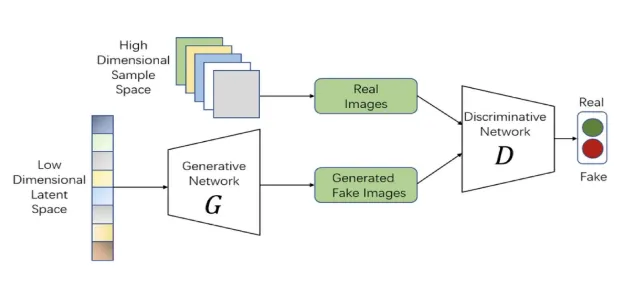
Fig. 1. GAN Model
The generative model types that can be used for image generation include GANs and VAEs, as shown in Fig. 1. The GAN is comprised of two competing models—the generator and discriminator. This helps generate real images from random noise; however, there could be issues like instability and mode collapse. VAEs use an encoder to convert images into a latent probabilistic distribution, which is decoded using the ELBO optimization technique to ensure smooth training. The downside to this model is that the generated output tends to be blurrier [11,12]. The figure below illustrates the VAEs model in detail.
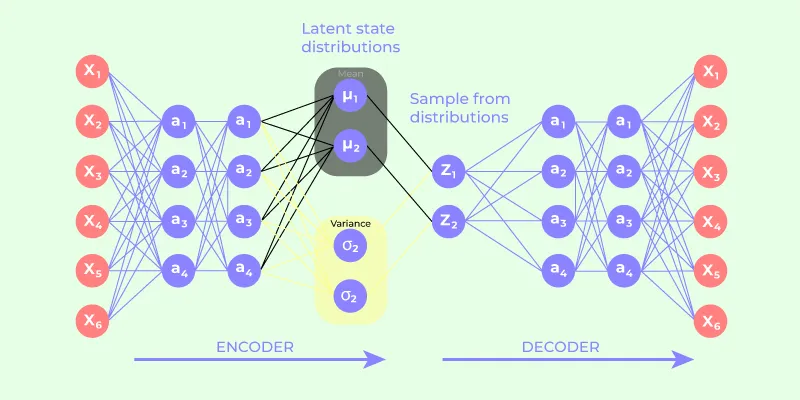
Fig.2. VAE Model
Fig. 2 shows the structure of the Variational Autoencoder (VAE). Images from the input are first compressed using an encoder and then mapped to a latent space expressed as a probability distribution through mean and variance values. Samples are then drawn from the latent space and fed to a decoder for reconstruction of the input image. The latent space in this case is expressed in probability distributions, ensuring a smooth and continuous latent space for efficient feature learning and interpolation.
Flow-based Models: Flow-based models compute accurate likelihoods and generate high-quality samples by learning invertible transformations between input and latent spaces. They train reliably, estimate density accurately, and infer efficiently. However, architectural constraints and computing complexity limit their use in high-resolution image production [12, 13]. An overview of flow-based models is illustrated in Fig. 3 below.
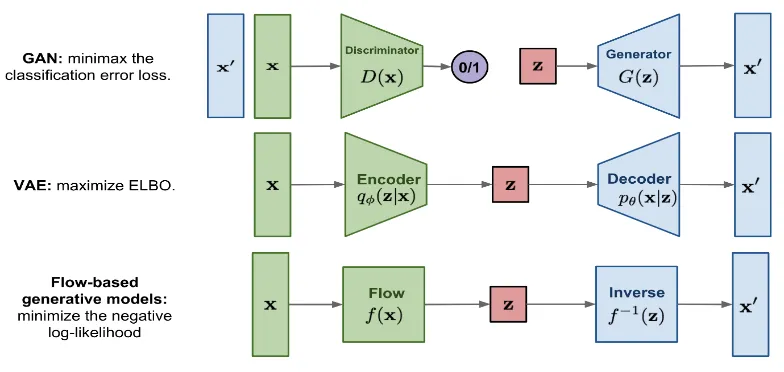
Fig. 3. Flow based models
Fig. 3 shows flow-based generative models, specifically diffusion models, where images can be generated using a series of steps that involve denoising until a clean image is generated from pure noise. In this case, the algorithm learns how to undo a diffusion process in steps by reducing the level of noise to reconstruct a realistic image. The step-by-step denoising process allows for the creation of more diverse, high-quality images while allowing better control over the results, making diffusion models the most advanced method of generating images [12, 13, 14]. The fig. 4 below illustrates the diffusion models in detail.
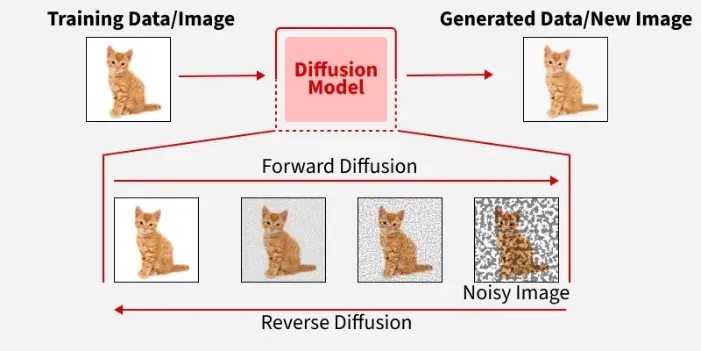
Fig. 4. Diffusion model
Fig. 4 illustrates the fundamental image generation paradigms based on diffusion and autoregressive models. The diffusion model operates by progressively adding noise to an image and then learning to reverse this process, enabling the generation of highly realistic and diverse outputs. This approach is known for its stability and quality, although it requires significant computational resources and longer generation time. In contrast, the autoregressive model generates images sequentially by predicting each pixel or token based on previously generated elements. This step-by-step generation allows for accurate probability estimation and fine-grained control over image synthesis, resulting in high-quality outputs. However, the sequential nature of the process leads to slower inference compared to parallel generation methods. These paradigms are also widely integrated into modern vision–language architectures for enhanced multimodal learning.
Fig. 5 further presents the detailed pipeline of autoregressive image generation, highlighting the sequential prediction process, dependency modeling, and iterative construction of the final image output.
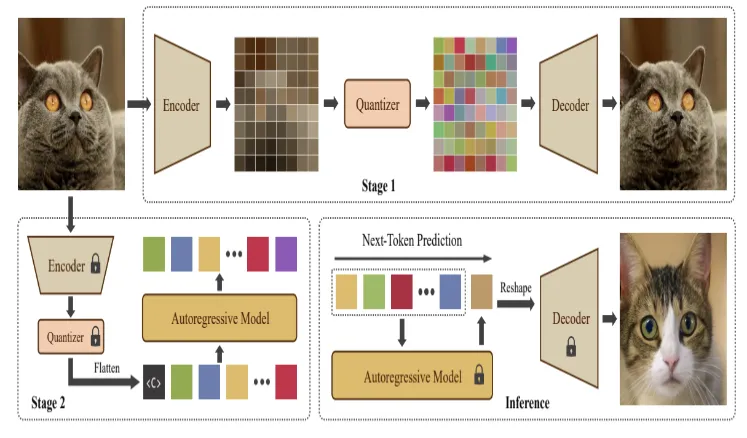
Fig. 5. Autoregressive image generation pipeline
Fig. 5 shows the autoregressive pipeline in image generation, which involves the generation of images in sequence, from pixel to pixel or from token to token, using generated information up until then as the context. This method is ideal for controlling the generation process and facilitates precise likelihood modeling and good quality synthetic image generation. On the other hand, such a sequence-dependent system becomes costly in terms of computations and takes more time to infer.
IV. IMAGE RECOGNITION: CONCEPTS AND CHALLENGES
The term image recognition refers to the automatic identification of objects, patterns, and features from visual data. It plays a critical role in modern applications such as medical diagnostics, autonomous vehicles, security surveillance, and industrial inspection. Traditionally, image recognition relied on handcrafted feature extraction combined with machine learning classifiers, often requiring strong domain expertise. However, these approaches struggled to handle complex variations in real-world images. The introduction of deep learning, particularly Convolutional Neural Networks (CNNs), transformed this field by enabling models to learn hierarchical feature representations directly from data, leading to improved accuracy, scalability, and adaptability. Despite these advancements, deep learning-based recognition systems still face several practical challenges. One major limitation is the scarcity of labeled data, especially in domains like medical imaging or rare object detection, where data collection and annotation are expensive and limited. Additionally, variations such as occlusion, illumination changes, and background complexity can significantly affect recognition performance. Domain shift is another concern, where models trained on one dataset may not generalize well to data from different environments or sensors. Furthermore, annotation noise can negatively impact learning by introducing incorrect labels during training. Generative AI offers effective solutions to these challenges by improving data quality, diversity, and robustness. Techniques such as data augmentation and synthetic sample generation help overcome data scarcity, while domain adaptation methods reduce the impact of distribution shifts. Moreover, generative approaches can simulate adversarial perturbations during training, enhancing model resilience against adversarial attacks [15], [16], [17]. By addressing these limitations, generative AI significantly enhances the reliability and real-world applicability of image recognition systems.
V. GENERATIVE AI TECHNIQUES APPLIED TO IMAGE RECOGNITION
Generative artificial intelligence plays a significant role in enhancing diversity, representation, and robustness of models, which can enhance image recognition. generative models create synthetic datasets, augment rare classes, and consider domain- and distance-varied samples, which can lessen the challenges associated with data scarcity. By providing latent representations, generative models allow for unsupervised or self-supervised ordering of feature learning paired with improvements in data fidelity. Image enhancement methods.
VI. STATE-OF-THE-ART GENERATIVE MODELS FOR IMAGE RECOGNITION
Several cutting-edge generative models used in image recognition are built on diverse architectural frameworks. These include Generative Adversarial Networks (GANs) such as Deep Convolutional GAN (DCGAN), Wasserstein GAN (WGAN), Style-based GAN (StyleGAN), and BigGAN, which are widely recognized for their ability to produce realistic image synthesis and effective feature learning. Variational Autoencoders (VAEs), including Beta-VAE (β-VAE), Vector Quantized VAE (VQ-VAE), and Hierarchical VAE, are employed to enhance latent space representation and interpretability. In addition, diffusion-based approaches such as Denoising Diffusion Probabilistic Models (DDPM), Denoising Diffusion Implicit Models (DDIM), Latent Diffusion Models (LDM), Imagen, and Stable Diffusion have achieved state-of-the-art performance in generating high-quality images. Vision–language models, including Contrastive Language–Image Pre-training (CLIP), DALL·E, and Flamingo, extend these capabilities by enabling multimodal understanding. Furthermore, hybrid architectures combine generative and discriminative techniques to improve robustness and recognition accuracy. Table 2 presents a detailed summary of these state-of-the-art methods [4], [5], [6], [7], [8].
Generative artificial intelligence has significantly enhanced data generation, feature extraction, and cross-modal understanding in image recognition tasks. In medical imaging, models such as GANs and diffusion techniques are used to improve magnetic resonance imaging (MRI) and computed tomography (CT) scans by reducing noise, enhancing clarity, and enabling high-resolution reconstruction for applications like cancer diagnosis and lesion segmentation. They also facilitate the generation of synthetic datasets, addressing data scarcity and privacy concerns in clinical environments. This growing importance has been highlighted in recent studies focusing on real-world recognition applications [14].
Beyond healthcare, generative AI plays a vital role in geospatial analytics and remote sensing by improving object detection, land-use classification, and atmospheric noise reduction. Techniques such as cloud removal and multispectral image synthesis enhance the interpretation of satellite and aerial imagery, while multimodal diffusion models support integrated analysis of complex datasets [6]. In autonomous systems, particularly self-driving vehicles, generative methods contribute to improved scene understanding by simulating challenging conditions such as low light, motion blur, and adverse weather. These capabilities strengthen system robustness and situational awareness, enabling more reliable decision-making in dynamic real-world environments.
VII. APPLICATIONS OF GENERATIVE AI IN IMAGE RECOGNITION
Generative Artificial Intelligence (AI) technology has made improvements in image recognition algorithms due to greater data diversity, quality images, and model robustness. In the healthcare industry, models like GANs and diffusion networks can be applied to improve the quality of MRI and CT scans via noise reduction, super-resolution and generation of synthetic medical images. This is especially useful when dealing with an insufficient number of annotated datasets.
For instance, in autonomous vehicles, generative AI helps simulate different types of driving environments, including fog, nighttime and other rare situations, which will lead to more robust recognition models for object detection and navigation in dynamic environments. In the field of security and surveillance, generative models allow one to generate variations in pose, lighting, and occlusions in order to make facial recognition systems more robust against adversarial attacks.
Overall, generative AI strengthens image recognition by addressing data scarcity and improving feature representation across multiple domains.
VIII. COMPARATIVE PERFORMANCE ANALYSIS OF GENERATIVE MODELS
To provide a clearer technical comparison between different generative architectures, Table 4 summarizes commonly reported benchmark performance metrics for GANs, VAEs, and diffusion models across image generation and recognition tasks.
|
Model Type |
Typical FID Score |
Image Quality |
Training Stability |
Strengths |
Limitations |
|
GAN |
10–25 |
Very High |
Medium |
High realism, fast inference |
Mode collapse, unstable training |
|
VAE |
40–80 |
Moderate |
High |
Stable training, interpretable latent space |
Blurry image generation |
|
Diffusion Models |
2–10 |
Extremely High |
Very High |
State-of-the-art image fidelity |
Slow sampling process |
TABLE II. COMPARATIVE PERFORMANCE OF GENERATIVE MODELS
Table 2 highlights the comparison between GANs, VAEs, and diffusion models in terms of FID score, quality of images, stability, computational efficiency, advantages, and disadvantages. The FID of GANs ranges from 10-25; they produce highly qualitative images; however, they have moderate stability and computational efficiency, with fast inference speed and prone to mode collapsing. VAEs
have better FID ranging from 40-80; they produce moderate-quality images and exhibit high stability and low computational efficiency due to their probabilistic nature, making blurred image generation.
|
Category |
Component |
Description / Findings |
Strengths & Weaknesses |
|
Benchmark Datasets |
ImageNet |
Large-scale Dataset widely used for classification benchmarking. |
Strength: High diversity; Weakness: Expensive to train on. |
|
|
CIFAR-10/100 |
Small, labelled datasets for rapid testing of generative–recognition models. |
Strength: Fast training; Weakness: Low resolution limits realism. |
|
|
COCO |
Used for detection, segmentation, and captioning tasks. |
Strength: Multi-task dataset; Weakness: Complex annotations. |
|
|
CelebA |
Face attributes and identity recognition benchmark. |
Strength: Good for GAN testing; Weakness: Domain-specific. |
|
|
MNIST |
Standard digit recognition dataset. |
Strength: Simple baseline; Weakness: Too easy for modern models. |
|
|
Custom Datasets |
Domain-specific datasets for medical, remote sensing, or industrial tasks. |
Strength: Real-world relevance; Weakness: Limited size and variability. |
|
|
MNIST |
Standard digit recognition dataset. |
Strength: Simple baseline; Weakness: Too easy for modern models. |
|
Evaluation Metrics |
PSNR (Peak Signal-to-Noise Ratio) |
Measures image reconstruction quality. |
Strength: Quantitative clarity; Weakness: Not aligned with human perception. |
|
|
SSIM (Structural Similarity Index) |
Evaluates structural fidelity between images. |
Strength: Perceptually aligned; Weakness: Still limited for complex textures. |
|
|
FID (Fréchet Inception Distance) |
Measures generative realism by comparing feature distributions. |
Strength: Widely adopted; Weakness: Sensitive to implementation variations. |
|
|
IS (Inception Score) |
Evaluates image quality and diversity. |
Strength: Simple; Weakness: Biased toward specific classes. |
|
|
Accuracy / Top-1 / Top-5 |
Measures recognition correctness. |
Strength: Universal metric; Weakness: Doesn’t capture robustness. |
|
|
MAP (Mean Average Precision) |
Detection Quality across thresholds. |
Strength: Comprehensive; Weakness: Harder interpret. |
|
|
IoU (Intersection over Union) |
Segmentation overlap |
Strength: Standardized; Weakness: Penalizes minor misalignment heavily. |
TABLE III. DATASET DETAILS AND PERFORMANCE EVALUATION DETAILS.
Table 3 gives an overview of common benchmarking data sets and evaluation metrics for applications in generative artificial intelligence and image recognition. Common benchmarking data sets include ImageNet, COCO, CIFAR-10/100, CelebA, MNIST, as well as other more specific data sets that can be designed for the particular domain of interest. Evaluation measures such as PSNR, SSIM, FID, IS, Accuracy, MAP, and IoU evaluate various aspects of image generation, including image reconstruction, perception quality, accuracy, and object detection and localization. However, there are certain limitations to each one of those measures.
IX. DISCUSSION: CHALLENGES, FUTURE DIRECTIONS, AND OVERALL INSIGHTS
While possessing many benefits, there exist a few limitations associated with the use of generative AI for image recognition problems.
For example, GANs tend to face instability and convergence during the training phase, whereas Diffusion models need massive computational power and longer time required for performing inference operations Moreover, ethical issues, non-standardized evaluation methods, and poor generalizability prevent wide application in practice. Finally, maintaining transparency and interpretability should be a crucial task for future work.
As for future directions, efforts should be made to ensure high energy efficiency and real-time operation of such models, as well as the incorporation of multimodal sensor fusion techniques and explainability. The application of large foundation models seems to improve the efficiency of such approaches in different areas. In conclusion, the literature review revealed the ability of generative AI models to increase the effectiveness of data utilization, learning, and image recognition.
Although generative artificial intelligence has demonstrated substantial potential in improving image recognition systems, several research challenges and gaps remain. Computational Efficiency Many state-of-the-art generative models, particularly diffusion-based architectures and large-scale GANs, require extensive computational resources for training and inference. These models typically depend on high-performance GPUs and large datasets, which limits their applicability in real-time and edge-computing environments. Future research should focus on developing lightweight generative architectures and energy-efficient training methods that can support deployment in resource-constrained systems.
Training instability remains a major challenge in adversarial generative models. GANs often suffer from issues such as mode collapse, gradient instability, and convergence difficulties. Although several improvements such as Wasserstein GAN and StyleGAN architectures have been proposed, achieving stable and reliable training across diverse datasets continues to be an open research problem.
Another significant gap is the lack of standardized evaluation benchmarks for generative AI applications in image recognition. Existing studies often rely on different datasets and performance metrics, making direct comparisons between models difficult. Establishing unified evaluation frameworks and benchmark datasets would enable more reliable assessment of generative model performance.
Most generative AI systems operate as black-box models, limiting interpretability in critical applications such as healthcare diagnostics, autonomous driving, and surveillance systems. Future research should investigate explainable generative AI approaches that improve transparency and support responsible decision-making.
The rapid development of generative AI technologies has also raised concerns regarding deepfakes, misinformation, and misuse of synthetic media. Addressing these challenges
requires interdisciplinary efforts involving algorithmic safeguards, ethical guidelines, and regulatory frameworks.
Future research should explore several promising directions, including:
CONCLUSION
This review found that generative AI has revolutionized picture identification with powerful data augmentation, feature learning, domain adaption, and image restoration capabilities. Numerous studies documented how boards improved recognition accuracy, data scarcity, and system resilience in difficult visual environments. Training instability, computational costs, and ethical implications remain concerns. Nevertheless, Difusion models, multimodal architectures, and energy-efficient techniques should represent potential pathways for innovation. generative AI is rapidly accelerating image recognition as it stimulates the creation of more intelligent and adaptive visual systems.
REFERENCES


Suvina Preethi Dsouza*, Janapati Venkata Krishna, A Systematic Review Of Generative AI In Computer Vision, Int. J. Sci. R. Tech., 2026, 3 (6), 337-348. https://doi.org/10.5281/zenodo.20555584
 10.5281/zenodo.20555584
10.5281/zenodo.20555584